Advantages of Microservices Architecture
|
|
Advantage
|
Description
|
Independent
Development
|
All microservices can be easily developed based on their individual
functionality
|
Independent
Deployment
|
Based on their services, they can be individually deployed in any
application
|
Fault Isolation
|
Even if one service of the application does not work, the system still
continues to function
|
Mixed Technology
Stack
|
Different languages and technologies can be used to build different
services of the same application
|
Granular Scaling
|
Individual components can scale as per need, there is no need to scale
all components together
|
- Microservices, aka Microservice Architecture, is an architectural style that structures an application as a collection of small autonomous services, modeled around a business domain.
- They initially start with a small section using various materials
and continue to build a large beehive out of it.
- These cells form a pattern resulting in a strong structure which
holds together a particular section of the beehive.
- Here, each cell is independent of the other but it is also
correlated with the other cells.
- This means that damage to one cell does not damage the other cells,
so, bees can reconstruct these cells without impacting the complete
beehive.

- Decoupling – Services within a
system are largely decoupled. So the application as a whole can be easily
built, altered, and scaled
- Componentization – Microservices are
treated as independent components that can be easily replaced and upgraded
- Business Capabilities –
Microservices are very simple and focus on a single capability
- Autonomy – Developers and teams
can work independently of each other, thus increasing speed
- Continous Delivery –
Allows frequent releases of software, through systematic automation of
software creation, testing, and approval
- Responsibility – Microservices do not
focus on applications as projects. Instead, they treat applications
as products for which they are responsible
- Decentralized Governance –
The focus is on using the right tool for the right job. That means there
is no standardized pattern or any technology pattern. Developers have
the freedom to choose the best useful tools to solve their problems
- Agility – Microservices
support agile development. Any new feature can be quickly developed and
discarded again
10 Microservices Best Practices
1. The Single Responsibility Principle
Just like with code, where a class should have only a single reason to change, microservices should be modeled in a similar fashion. Building bloated services which are subject to change for more than one business context is a bad practice.
Example: Let’s say you are building microservices for ordering a pizza. You can consider building the following components based on the functionality each supports like InventoryService, OrderService, PaymentsService, UserProfileService, DeliveryNotificationService, etc. InventoryService would only have APIs that fetch or update the inventory of pizza types or toppings, and likewise others would carry the APIs for their functionality.
2. Have a separate data store(s) for your microservice
It defeats the purpose of having microservices if you are using a monolithic database that all your microservices share. Any change or downtime to that database would then impact all the microservices that use the database. Choose the right database for your microservice needs, customize the infrastructure and storage to the data that it maintains, and let it be exclusive to your microservice. Ideally, any other microservice that needs access to that data would only access it through the APIs that the microservice with write access has exposed.
3. Use asynchronous communication to achieve loose coupling
To avoid building a mesh of tightly coupled components, consider using asynchronous communication between microservices.
a. Make calls to your dependencies asynchronously, example below.
Example: Let’s say you have a Service A that calls Service B. Once Service B returns a response, Service A returns success to the caller. If the caller is not interested in Service B’s output, then Service A can asynchronously invoke Service B and instantly respond with a success to the caller.
b. An even better option is to use events for communicating between microservices. Your microservice would publish an event to a message bus either indicating a state change or a failure and whichever microservice is interested in that event, would pick it up and process it.
Example: In the pizza order system above, sending a notification to the customer once their order is captured, or status messages as the order gets fulfilled and delivered, can happen using asynchronous communication. A notification service can listen to an event that an order has been submitted and process the notification to the customer.
4. Fail fast by using a circuit breaker to achieve fault tolerance
If your microservice is dependent on another system to provide a response, and that system takes forever to respond, your overall response SLAs will be impacted. To avoid this scenario and quickly respond, one simple microservices best practice you can follow is to use a circuit breaker to timeout the external call and return a default response or an error. The Circuit Breaker pattern is explained in the references below. This will isolate the failing services that your service is dependent on without causing cascade failures, keeping your microservice in good health. You can choose to use popular products like Hystrix that Netflix developed. This is better than using the HTTP CONNECT_TIMEOUT and READ_TIMEOUT settings as it does not spin up additional threads beyond what’s been configured.
5. Proxy your microservice requests through an API Gateway
Instead of every microservice in the system performing the functions of API authentication, request / response logging, and throttling, having an API gateway doing these for you upfront will add a lot of value. Clients calling your microservices will connect to the API Gateway instead of directly calling your service. This way you will avoid making all those additional calls from your microservice and the internal URLs of your service would be hidden, giving you the flexibility to redirect the traffic from the API Gateway to a newer version of your service. This is even more necessary when a third party is accessing your service, as you can throttle the incoming traffic and reject unauthorized requests from the API gateway before they reach your microservice. You can also choose to have a separate API gateway that accepts traffic from external networks.
6. Ensure your API changes are backwards compatible
You can safely introduce changes to your API and release them fast as long as they don’t break existing callers. One possible option is to notify your callers , have them provide a sign off for your changes by doing integration testing. However, this is expensive, as all the dependencies need to line up in an environment and it will slow you down with a lot of coordination . A better option is to adopt contract testing for your APIs. The consumers of your APIs provide contracts on their expected response from your API. You as a provider would integrate those contract tests as part of your builds and these will safeguard against breaking changes. The consumer can test against the stubs that you publish as part of the consumer builds. This way you can go to production faster with independently testing your contract changes.
7. Version your microservices for breaking changes
It's not always possible to make backwards compatible changes. When you are making a breaking change, expose a new version of your endpoint while continuing to support older versions. Consumers can choose to use the new version at their convenience. However, having too many versions of your API can create a nightmare for those maintaining the code. Hence, have a disciplined approach to deprecate older versions by working with your clients or internally rerouting the traffic to the newer versions.
8. Have dedicated infrastructure hosting your microservice
You can have the best designed microservice meeting all the checks, but with a bad design of the hosting platform it would still behave poorly. Isolate your microservice infrastructure from other components to get fault isolation and best performance. It is also important to isolate the infrastructure of the components that your microservice depends on.
Example: In the pizza order example above, let's say the inventory microservice uses an inventory database. It is not only important for the Inventory Service to have dedicated host machines, but also the inventory database needs to have dedicated host machines.

- Clients – Different users from
various devices send requests.
- Identity Providers – Authenticates user
or clients identities and issues security tokens.
- API Gateway – Handles client
requests.
- Static Content – Houses all the
content of the system.
- Management – Balances
services on nodes and identifies failures.
- Service Discovery – A guide to find the
route of communication between microservices.
- Content Delivery Networks –
Distributed network of proxy servers and their data centers.
- Remote Service – Enables the remote
access information that resides on a network of IT devices.
Pros of Microservice Architecture
|
Cons of Microservice Architecture
|
Freedom to use different
technologies
|
Increases troubleshooting
challenges
|
Each microservices focuses on
single capability
|
Increases delay due to remote calls
|
Supports individual deployable
units
|
Increased efforts for configuration
and other operations
|
Allow frequent software releases
|
Difficult to maintain transaction
safety
|
Ensures security of each service
|
Tough to track data across various
boundaries
|
Mulitple services are parallelly
developed and deployed
|
Difficult to code between services
|

- Monolithic Architecture is
similar to a big container wherein all the software components of an
application are assembled together and tightly packaged.
- A Service-Oriented Architecture is a collection of
services which communicate with each other. The communication can involve
either simple data passing or it could involve two or more services
coordinating some activity.
- Microservice Architecture is
an architectural style that structures an application as a collection of
small autonomous services, modeled around a business domain.
- Automate the Components:
Difficult to automate because there are a number of smaller components. So
for each component, we have to follow the stages of Build, Deploy
and, Monitor.
- Perceptibility: Maintaining a large number
of components together becomes difficult to deploy, maintain, monitor and
identify problems. It requires great perceptibility around all the
components.
- Configuration Management:
Maintaining the configurations for the components across the various
environments becomes tough sometimes.
- Debugging: Difficult to find out each
and every service for an error. It is essential to maintain centralized
logging and dashboards to debug problems.
SOA
|
Microservices
|
Follows “share-as-much-as-possible”
architecture approach
|
Follows “share-as-little-as-possible”
architecture approach
|
Importance is on business functionality reuse
|
Importance is on the concept of “bounded
context”
|
They have common governance and
standards
|
They focus on people collaboration and
freedom of other options
|
Uses Enterprise Service bus
(ESB) for communication
|
Simple messaging system
|
They support multiple
message protocols
|
They use lightweight
protocols such as HTTP/REST etc.
|
Multi-threaded with more overheads to handle I/O
|
Single-threaded usually with the use of Event Loop features for non-locking I/O
handling
|
Maximizes application service
reusability
|
Focuses on decoupling
|
Traditional Relational Databases are more often used
|
Modern Relational
Databases are more often used
|
A systematic change requires
modifying the monolith
|
A systematic change is to create a
new service
|
DevOps / Continuous Delivery is
becoming popular, but not yet mainstream
|
Strong focus on DevOps / Continuous
Delivery
|


- A dummy object that helps in running the test.
- Provides fixed behavior under certain conditions which can be
hard-coded.
- Any other behavior of the stub is never tested.
- A dummy object in which certain properties are set initially.
- The behavior of this object depends on the set properties.
- The object’s behavior can also be tested.
- Decides broad strokes about the layout of the overall software
system.
- Helps in deciding the zoning of the components. So, they make sure
components are mutually cohesive, but not tightly coupled.
- Code with developers and learn the challenges faced in day-to-day
life.
- Make recommendations for certain tools and technologies to the team
developing microservices.
- Provide technical governance so that the teams in their technical
development follow principles of Microservice.
A: Spring Boot provides actuator endpoints to monitor metrics of individual microservices. These endpoints are very helpful for getting information about applications like if they are up, if their components like database etc are working good. But a major drawback or difficulty about using actuator enpoints is that we have to individually hit the enpoints for applications to know their status or health. Imagine microservices involving 50 applications, the admin will have to hit the actuator endpoints of all 50 applications. To help us deal with this situation, we will be using open source project located at https://github.com/codecentric/spring-boot-admin.
Built on top of Spring Boot Actuator, it provides a web UI to enable us visualize the metrics of multiple applications.
Spring Boot Admin Example
Q: What does one mean by Service Registration and Discovery ? How is it implemented in Spring Cloud
A: When we start a project, we usally have all the configurations in the properties file. As more and more services are developed and deployed, adding and modifying these properties become more complex. Some services might go down, while some the location might change. This manual changing of properties may create issues.
Eureka Service Registration and Discovery helps in such scenarios. As all services are registered to the Eureka server and lookup done by calling the Eureka Server, any change in service locations need not be handled and is taken care of
Microservice Registration and Discovery with Spring cloud using Netflix Eureka.
Q: What are the different Microservices Design Patterns?
A: The different Microservices Design Patterns are -
- Aggregator Microservice Design Pattern
- API Gateway Design Pattern
- Chain of Responsibility Design Pattern
- Branch Microservice Design Pattern
- Circuit Breaker Design Pattern
- Asynchronous Messaging Design Pattern
Q: What does one mean by Load Balancing ? How is it implemented in Spring Cloud
A: In computing, load balancing improves the distribution of workloads across multiple computing resources, such as computers, a computer cluster, network links, central processing units, or disk drives. Load balancing aims to optimize resource use, maximize throughput, minimize response time, and avoid overload of any single resource. Using multiple components with load balancing instead of a single component may increase reliability and availability through redundancy. Load balancing usually involves dedicated software or hardware, such as a multilayer switch or a Domain Name System server process.
In SpringCloud this can be implemented using Netflix Ribbon.
Spring Cloud- Netflix Eureka + Ribbon Simple Example
Q: How to achieve server side load balancing using Spring Cloud?
A: Server side load balancingcan be achieved using Netflix Zuul.
Zuul is a JVM based router and server side load balancer by Netflix.
It provides a single entry to our system, which allows a browser, mobile app, or other user interface to consume services from multiple hosts without managing cross-origin resource sharing (CORS) and authentication for each one. We can integrate Zuul with other Netflix projects like Hystrix for fault tolerance and Eureka for service discovery, or use it to manage routing rules, filters, and load balancing across your system.
Spring Cloud- Netflix Zuul Example
Q: In which business scenario to use Netflix Hystrix ?
A: Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
Usually for systems developed using Microservices architecture, there are many microservices involved. These microservices collaborate with each other.
Consider the following microservices-

This problem gets more complex as the number of microservices increase. The number of microservices can be as high as 1000. This is where hystrix comes into picture-
We will be using two features of Hystrix-
- Fallback method
- Circuit Breaker
Q: What is Spring Cloud Gateway? What are its advantages over Netflix Zuul?
A: Zuul is a blocking API. A blocking gateway api makes use of as many threads as the number of incoming requests. So this approach is more resource intensive. If no threads are available to process incoming request then the request has to wait in queue.
In this tutorial we will be implementing API Gateway using Spring Cloud Gateway. Spring Cloud Gateway is a non blocking API. When using non blocking API, a thread is always available to process the incoming request. These request are then processed asynchronously in the background and once completed the response is returned. So no incoming request never gets blocked when using Spring Cloud Gateway.
Spring Cloud Gateway Tutorial - Hello World Example
Q: What is Spring Cloud Bus? Need for it?
A: Consider the scenario that we have multiple applications reading the properties using the Spring Cloud Config and the Spring Cloud Config in turn reads these properties from GIT.
Consider the below example where multiple employee producer modules are getting the property for Eureka Registration from Employee Config Module.


The Spring Cloud Bus provides feature to refresh configurations across multiple instances. So in above example if we refresh for Employee Producer1, then it will automatically refresh for all other required modules. This is particularly useful if we are having multiple microservice up and running. This is achieved by connecting all microservices to a single message broker. Whenever an instance is refreshed, this event is subscribed to all the microservices listening to this broker and they also get refreshed. The refresh to any single instance can be made by using the endpoint /bus/refresh
Spring Cloud Tutorial - Publish Events Using Spring Cloud Bus
Q: What is Spring Cloud Data Flow? Need for it?
A: Spring Cloud Data Flow is a toolkit to build real-time data integration and data processing pipelines by establishing message flows between Spring Boot applications that could be deployed on top of different runtimes.

In this example we make use of Stream Applications. Previously we had already developed Spring Cloud Stream applications to understand the concept of Spring Cloud Stream Source and Spring Cloud Sink and their benefit.

Pipelines consist of Spring Boot apps, built using the Spring Cloud Stream or Spring Cloud Task microservice frameworks. SCDF can be accessed using the REST API exposed by it or the web UI console.
We can make use of metrics, health checks, and the remote management of each microservice application Also we can scale stream and batch pipelines without interrupting data flows. With SCDF we build data pipelines for use cases like data ingestion, real-time analytics, and data import and export. SCDF is composed of the following Spring Projects-

Spring Cloud Tutorial - Stream Processing Using Spring Cloud Data Flow
Q:What is Docker? How to deploy Spring Boot Microservices to Docker?
A: What is Docker
Deploying Spring Based WAR Application to Docker
Deploying Spring Based JAR Application to Docker
A: Deploying Multiple Spring Boot Microservices using Docker Networking
Q: What is Pivotal Cloud Foundry(PCF)?
A: Some time back all the IT infrastructure was on premises. There we in house servers managed by an IT resource personnel or a service provider.
Then with advent of cloud services these software and hardware services are now delivered over the internet rather than being on premises.

Cloud Foundry is an open source, multi-cloud application platform as a service governed by the Cloud Foundry Foundation. The software was originally developed by VMware and then transferred to Pivotal Software, a joint venture by EMC, VMware and General Electric.
It is a service (PaaS) on which developers can build, deploy, run and scale applications.
Many Organizations provide the cloud foundry platform separately. For example following are some cloud foundry providers-
- Pivotal Cloud Foundry
- IBM Bluemix
- HPE Helion Stackato 4.0
- Atos Canopy
- CenturyLink App Fog
- Huawei FusionStage
- SAP Cloud Platform
- Swisscom Application Cloud
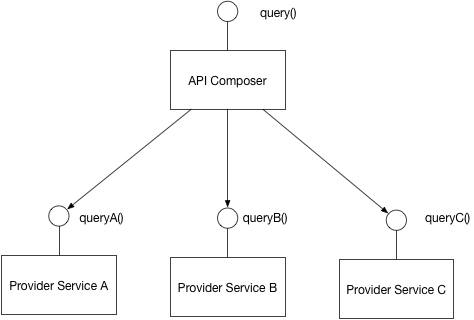
You have applied the Microservices architecture pattern and the Database per service pattern. As a result, it is no longer straightforward to implement queries that join data from multiple services.
Problem
How to implement queries in a microservice architecture?
Solution
Implement a query by defining an API Composer, which invoking the services that own the data and performs an in-memory join of the results.